
7 min read
.png)
At OnceHub, delivering business critical notifications as soon as they occur is at the core of our business.
If you are looking to design a fault tolerant, highly available, and scalable solution for delivering notifications to your customers, we would like to take you on a journey of how we built it and how you can do it too.
First a little background about why we built it. Our customers can register webhooks from the application if they want to be notified about key events in their pipelines. When these events occur, our application makes HTTP requests to such webhooks URLs along with the data. This way our customers can build custom integrations with OnceHub.
Let’s chisel out the requirements for such a system. The system should be able to:
- Handle millions of events occurring per second
- Deliver webhooks
- Retry the failed webhooks for a few times before giving up
- Easy to maintain and monitor.
Identifying the events
As events are going to be the centerpiece of our architecture, we need to identify the key events in our system. Since we offer a scheduling solution, the following were some of the events we identified.
meetings.scheduled
meetings.cancelled
Similarly you can list down the events which make sense to your business.
An event can also have some accompanying data. In our system it was the meeting details. We can encapsulate the event and its corresponding data in a data structure as shown below.
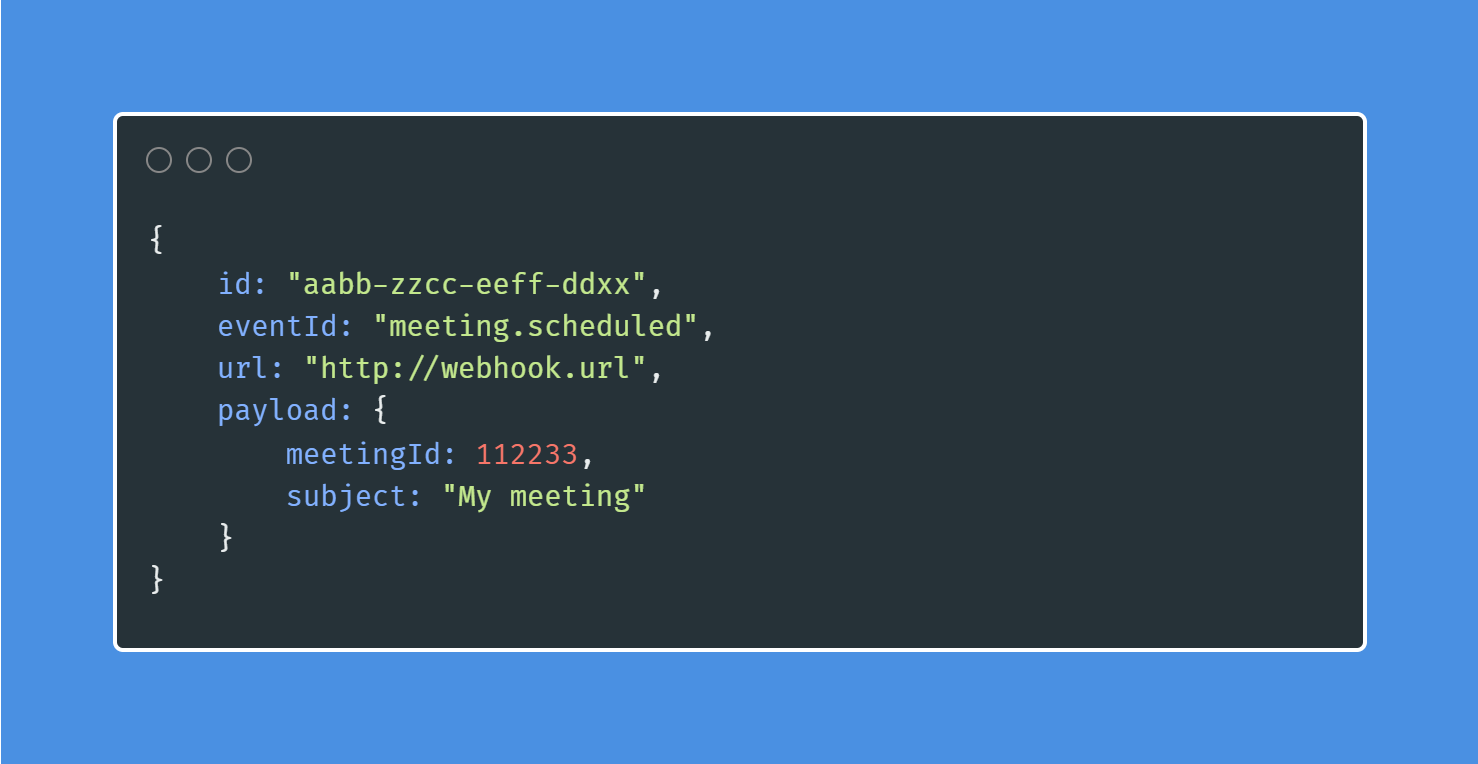
An example event
Deciding on the tech stack
Once we have the events listed down, we need to establish a way to pass such events along with their data from the originating micro-services to the one which will ultimately consume these events and deliver the webhooks.
Apache Kafka (Kafka, from this point onwards) offers a reliable way to achieve this sort of message passing between systems.
In our organization, we had already been using Apache Kafka so we had the inhouse expertise but fret not if this is your first time dealing with Apache Kafka. I will keep this guide as high level as possible.
Let’s see how an event based distributed system built on Kafka would look like.
- Certain systems will generate events.
- All such events will get pushed to a Kafka topic.
- All pushed events will be read sequentially by a consumer running inside a new microservice.
- This microservice will deliver the webhooks.
The initial design
Following is the gist of how our design is supposed to work
- Events get pushed to a Kafka topic
- A microservice will consume the events and read the database to see if any webhook is registered for the event being consumed
- If there is one, it will deliver the webhook
After the delivery attempt (irrespective of the status of the delivery i.e. success or failure) or if no registered webhook was found for the event being consumed, the service will drop the event and move on to the next one.
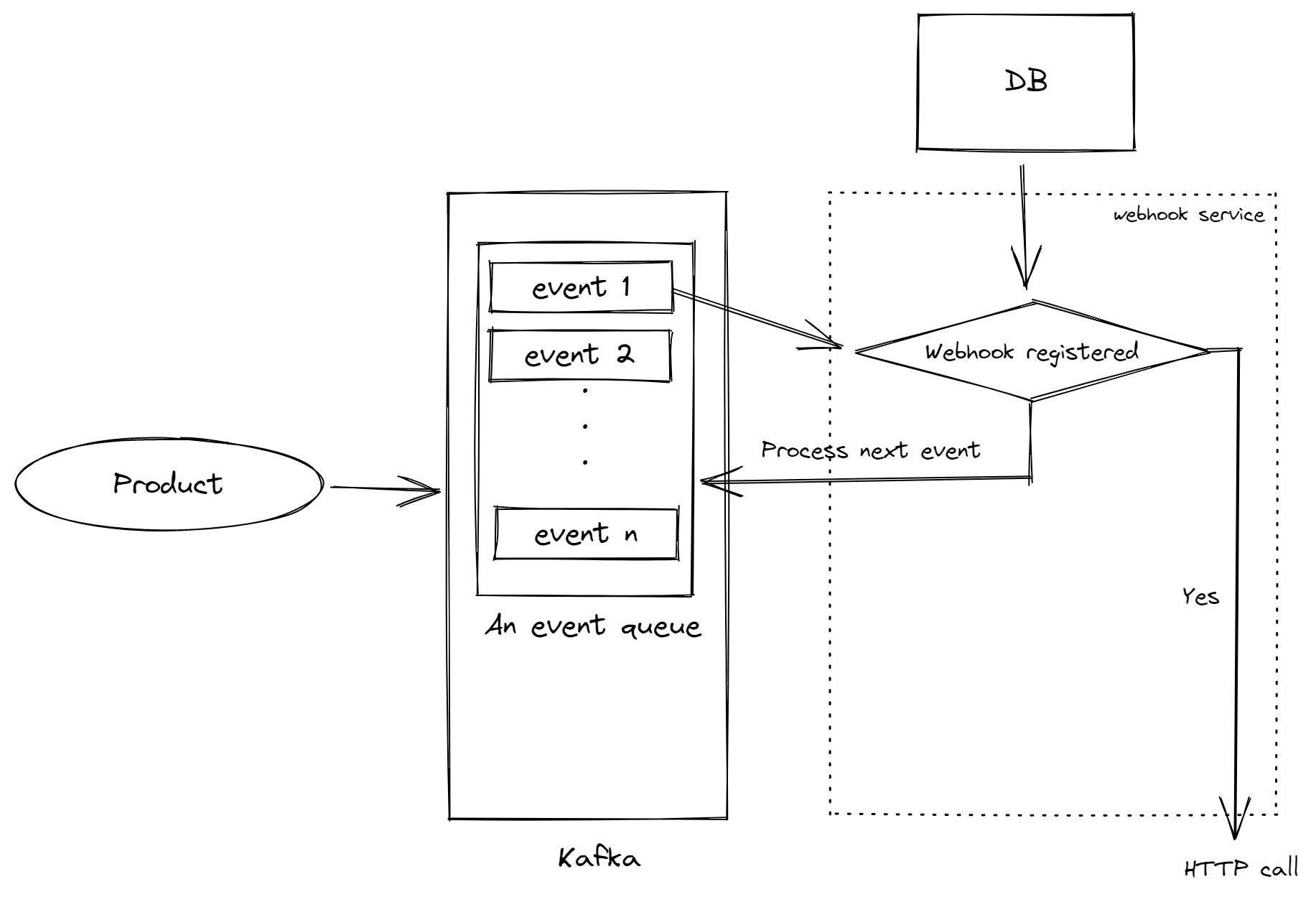
Using this design, you will be able to deliver webhooks reliably as Kafka can handle a high amount of events generated by our systems.
This design does not answer a key requirement though!
What if an HTTP call to the user’s webhook fails? The user’s destination might be unavailable either due to maintenance or something else. The system should retry the failed webhooks a couple of times before giving up.
You need to sit down with your team to see what retry strategy makes the most sense to your business. Our team decided that a good approach would be to retry for three consecutive days with an exponential increase in the time gap between the consecutive attempts.
For implementing the retry feature we need something that can run the failed webhook after a certain period of time. There are a lot of solutions for implementing such a feature including cronjobs, rabbitmq and many more.
If you are also as reluctant as we were to add more pieces to the puzzle, you can achieve the same result using your existing setup.
Webhook delivery with retries
Implementing retries with the existing setup is going to be simple. You would need to have a date property (let’s call it dueDate) which will represent how soon an event should be delivered and a counter property (let’s call it retryCount) to keep track of how many times a webhook has been attempted to be sent.
If a webhook fails, the system will calculate the next delivery time based on the retryCount property and overwrite dueDate of the webhook and push the event back again to the Kafka topic. This will create a loop. Remember this loop as we are going to meet it in future as well.
Following is the entire workflow of what we just described.
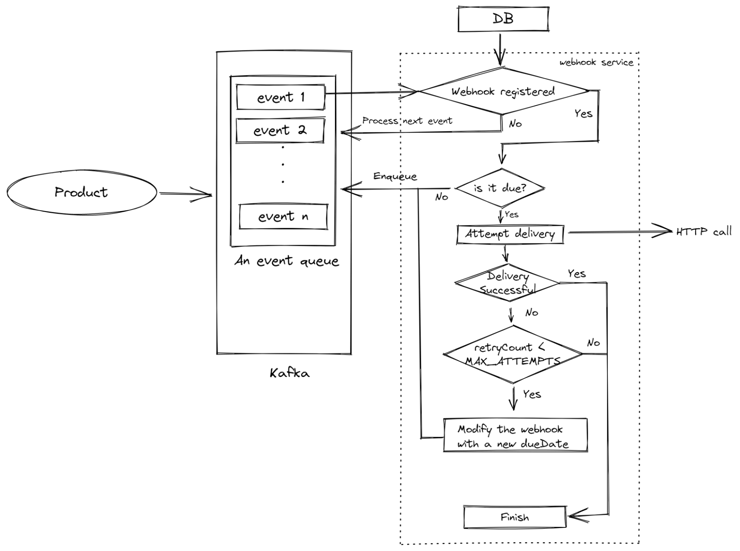
That’s it! You now have a good enough solution which will help you in delivering webhooks with ease.
Troubleshooting common issues
If you are going to use this very setup, there are certain issues you may run into (as we did). Following are the issues you may encounter and how to solve those.
Problem #1: Kafka cluster can run out of space
Since we have a “loop” in our architecture which re-enqueues an event over and over if it is not due, the Kafka disk space may run out.
This happens because the loop generates data faster than the rate Kafka could consume.
Thankfully, Kafka offers something known as retention settings to control how the disk space is utilized by Kafka. One can free up the space based on either time elapsed or memory consumed or both.
To free up the space, you can use the following retention settings and tweak the value as per your resources.
retention.bytes
retention.ms
You can read more about such settings from here.
Problem #2: Webhooks may get delayed
As there is a single topic for both fresh (never attempted) and failed webhooks, you may run into a situation where there are a lot of failed webhooks sitting in front of a fresh webhook.
As Kafka processes the messages sequentially, this will result in the fresh webhooks getting delayed. This issue can further be intensified by having too many partitions as compared to the number of consumers.
To solve this, we can have a separate topic for failed webhooks. This way the fresh webhooks will not get blocked by the failed ones.
Creating a separate topic for the failed webhooks served us really well and we ran this in production for five months.
The infinite loop is still here but it is now only operating on the failed webhooks topic. You may still encounter some delay but it will only be seen in case of the failed webhooks.
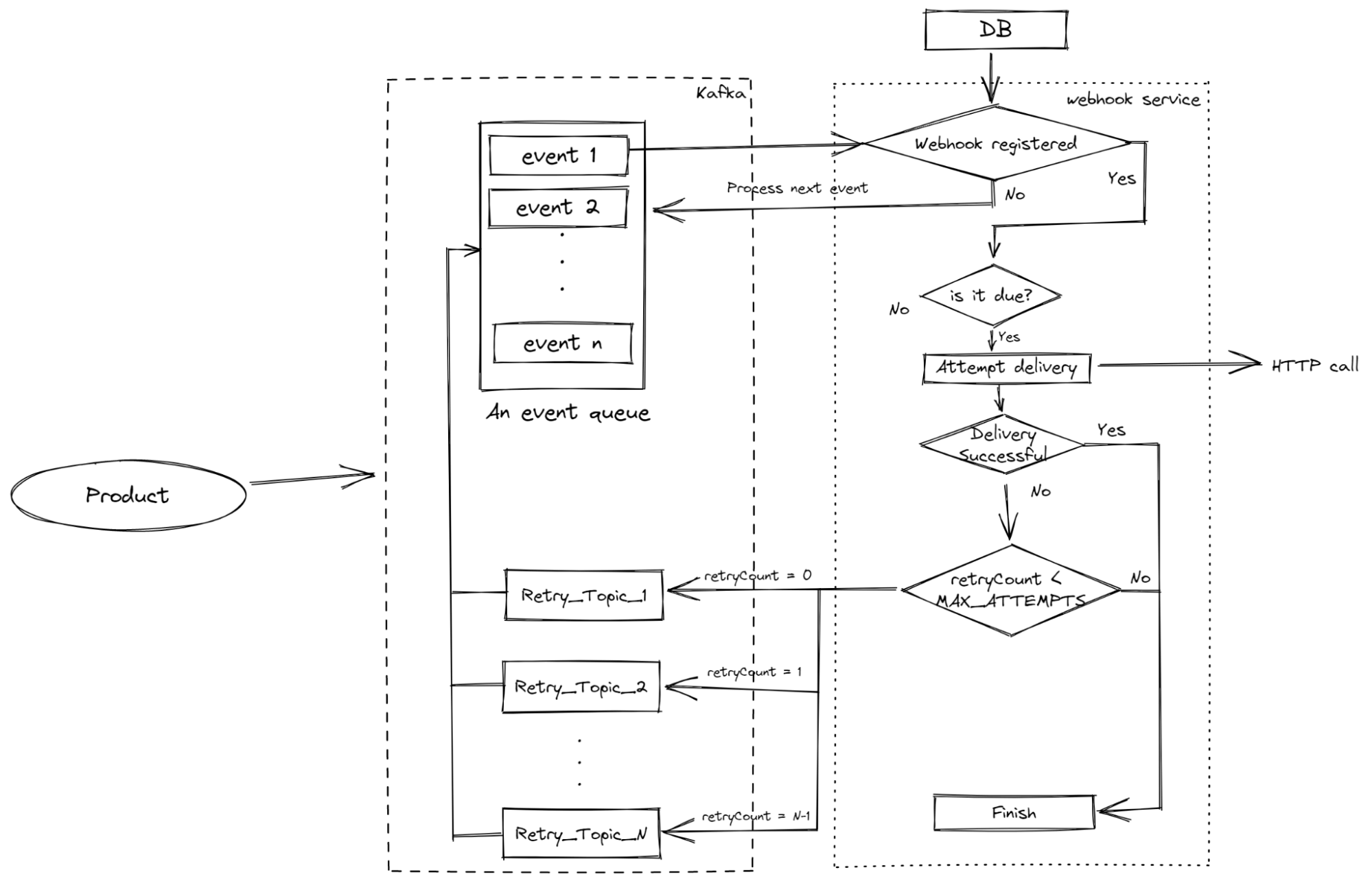
Problem #3: Consumer lag becomes too much on the retry topic
If you don’t want to have a lag even on the retry topic, you can ditch the loop altogether but that will require some restructuring.
In this new architecture, instead of having a single topic for all failed webhooks (irrespective of how many times they had been retried), there will be a separate topic for each retry attempt i.e. Topic RETRY_ONE will contain all the failed webhooks which have never been re-attempted, RETRY_TWO will contain failed webhooks which have been re-attempted once and so on.
The retry consumer subscribes to all such retry topics. This consumer resumes and pauses based on partitions and topics.
To do this, you can use Node.js’ setTimeout utility (or a similar utility in your language of choice) to schedule a background job. When the timer runs out, the failed webhook is pushed back to the primary topic responsible for delivering.
Here is the flow diagram of what we just described.
Following is a TypeScript implementation of the same. Feel free to use the code as is or as an inspiration.
.png?width=1140&name=image1%20(1).png)
This brings us to the conclusion of this article but it is just a beginning for us. We will update this article if we have more to share in future so watch this space.
We have written this article in the hope that it will be able to help someone out there. It is our way to contribute back to the community which we have learnt so much from.
If you implement a solution inspired by this article, we will be happy to learn about your experience and learning. You can reach out to us at <oncehub’s public email address>.
Rajat Saxena, Software Engineer
Rajat started as a Java developer in 2011 and later transitioned into a full stack developer,specializing in the JavaScript stack. He's worked as a Software Engineer at OnceHub since June 2019 where he focuses on microservices built with Node and portals built with Angular and React. In his free time, he enjoys playing Apex Legends (a video game) and learning random stuff about history and tech.